320x100
이번 섹션도 참... 알겠는듯 모르겠는 난해함들이 많았다.
정확한 표현으로는 들을땐 알겠는데, 듣는 과정에서 적용해보는 것을 이미지로 연상해보자면
반반?
아무튼 이제는 기계 주입식으로 좀 공부스타일을 바꿔볼까도 생각을 한다.
# Data Preparation and Feature Creation
## Arithmetic Operations
import pandas as pd
import numpy as np
titanic = pd.read_csv('titanic.csv')
titanic.head(10)
'''
survived pclass sex age sibsp parch fare embarked deck
0 0 3 male 22.0 1 0 7.2500 S NaN
1 1 1 female 38.0 1 0 71.2833 C C
2 1 3 female 26.0 0 0 7.9250 S NaN
3 1 1 female 35.0 1 0 53.1000 S C
4 0 3 male 35.0 0 0 8.0500 S NaN
5 0 3 male NaN 0 0 8.4583 Q NaN
6 0 1 male 54.0 0 0 51.8625 S E
7 0 3 male 2.0 3 1 21.0750 S NaN
8 1 3 female 27.0 0 2 11.1333 S NaN
9 1 2 female 14.0 1 0 30.0708 C NaN
'''titanic.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 deck 203 non-null object
dtypes: float64(2), int64(4), object(3)
memory usage: 62.8+ KB
'''
# 확인했을때, 특히 deck, sex 컬럼에 결측값이 있다.# 결측값 채우기 fillna
titanic.age.fillna(titanic.age.mean(), inplace = True)titanic.head(10)
'''
survived pclass sex age sibsp parch fare embarked deck
0 0 3 male 22.000000 1 0 7.2500 S NaN
1 1 1 female 38.000000 1 0 71.2833 C C
2 1 3 female 26.000000 0 0 7.9250 S NaN
3 1 1 female 35.000000 1 0 53.1000 S C
4 0 3 male 35.000000 0 0 8.0500 S NaN
5 0 3 male 29.699118 0 0 8.4583 Q NaN
6 0 1 male 54.000000 0 0 51.8625 S E
7 0 3 male 2.000000 3 1 21.0750 S NaN
8 1 3 female 27.000000 0 2 11.1333 S NaN
9 1 2 female 14.000000 1 0 30.0708 C NaN
'''
# 기존에 있던 결측값이 age 컬럼의 평균으로 채워졌다.## Add/Sub/Mul/Div of Columns
# 형제,자매와 부모자식을 더해주면 가족의 수가 나오기때문에 더해준다.
titanic.sibsp + titanic.parch
'''
0 1
1 1
2 0
3 1
4 0
..
886 0
887 0
888 3
889 0
890 0
Length: 891, dtype: int64
'''# 형제,자매와 부모자식을 더해주면 가족의 수가 나오기때문에 더해준다. 이것도 마찬가지
# 무언가를 더해줄때는 +보다는 add가 기능이 더 좋다고 한다.
# 이유는 나중에 알려준다고 한다.
titanic.sibsp.add(titanic.parch)
'''
0 1
1 1
2 0
3 1
4 0
..
886 0
887 0
888 3
889 0
890 0
Length: 891, dtype: int64
'''titanic['no_relat'] = titanic.sibsp.add(titanic.parch)
titanic.head()
'''
survived pclass sex age sibsp parch fare embarked deck no_relat
0 0 3 male 22.0 1 0 7.2500 S NaN 1
1 1 1 female 38.0 1 0 71.2833 C C 1
2 1 3 female 26.0 0 0 7.9250 S NaN 0
3 1 1 female 35.0 1 0 53.1000 S C 1
4 0 3 male 35.0 0 0 8.0500 S NaN 0
'''sales = pd.read_csv('sales.csv', index_col = 0)
sales
'''
Mon Tue Wed Thu Fri
Steven 34 27 15 NaN 33
Mike 45 9 74 87.0 12
Andi 17 33 54 8.0 29
Paul 87 67 27 45.0 7
'''sales.Mon + sales.Thu
'''
Steven NaN
Mike 132.0
Andi 25.0
Paul 132.0
dtype: float64
'''sales.Mon.add(sales.Thu)
'''
Steven NaN
Mike 132.0
Andi 25.0
Paul 132.0
dtype: float64
'''
# add 가 좋은 점이 1+ 결측값은 결측값이지만
# add로 추가해주면 결측값은 무시된다.
# 하지만 add를 +와 다르게 사용해주려면 매개변수를 지정해줘야한다.# add로 매개변수 fill_value를 이용하여 결측값을 0으로 바꾸기
sales.Mon.add(sales.Thu, fill_value =0)
'''
Steven 34.0
Mike 132.0
Andi 25.0
Paul 132.0
dtype: float64
'''
# 결과적으로 봤을때 숫자 + 결측값 = 결측값이다
# 하지만 fill_value를 0으로해줌으로써 Mon의 값 + 0으로 해줬기 때문에 Mon의 값이 리턴되는 것이다.sales['perc_Bonus'] = [0.12, 0.15, 0.10, 0.20]sales
'''
Mon Tue Wed Thu Fri perc_Bonus
Steven 34 27 15 NaN 33 0.12
Mike 45 9 74 87.0 12 0.15
Andi 17 33 54 8.0 29 0.10
Paul 87 67 27 45.0 7 0.20
'''sales.Thu * sales.perc_Bonus
'''
Steven NaN
Mike 13.05
Andi 0.80
Paul 9.00
dtype: float64
'''sales.Thu.mul(sales.perc_Bonus, fill_value = 0)
'''
Steven 0.00
Mike 13.05
Andi 0.80
Paul 9.00
dtype: float64
'''
# 어떤 수든 0을 곱하면 0이다.# -1를 해주는 이유는, 마지막 컬럼인 보너스 컬럼은 배제시키기 위해서다.
# 근본적으로 보너스가 얼마인지 계산해 주는 것이다.
# 재밌는 것은 여기서 쓰는 sum과 mul등은 결측값을 스킵해준다.
# 약간 이해가 안되는 점은 '컬럼'을 기준으로 더해주고, 다 더해진 값에 보너스 비율을 곱해준다.
sales.iloc[:, :-1].sum(axis = 1).mul(sales.perc_Bonus)
'''
Steven 13.08
Mike 34.05
Andi 14.10
Paul 46.60
dtype: float64
'''# 컬럼 추가
sales['Bonus'] = sales.iloc[:,:-1].sum(axis = 1).mul(sales.perc_Bonus)sales
'''
Mon Tue Wed Thu Fri perc_Bonus Bonus
Steven 34 27 15 NaN 33 0.12 13.08
Mike 45 9 74 87.0 12 0.15 34.05
Andi 17 33 54 8.0 29 0.10 14.10
Paul 87 67 27 45.0 7 0.20 46.60
'''## Add/Sub/Mul/Div with Scaler Value
import pandas as pd
titanic = pd.read_csv('titanic.csv')
titanic.head()
'''
survived pclass sex age sibsp parch fare embarked deck
0 0 3 male 22.0 1 0 7.2500 S NaN
1 1 1 female 38.0 1 0 71.2833 C C
2 1 3 female 26.0 0 0 7.9250 S NaN
3 1 1 female 35.0 1 0 53.1000 S C
4 0 3 male 35.0 0 0 8.0500 S NaN
'''# 출생연도 추정
# 1912를 써주는 이유는 타이타닉 사건 발생년도가 1912년 이였다.
1912 - titanic.age
'''
0 1890.0
1 1874.0
2 1886.0
3 1877.0
4 1877.0
...
886 1885.0
887 1893.0
888 NaN
889 1886.0
890 1880.0
Name: age, Length: 891, dtype: float64
'''# YoB는 출생연도 구하기
# sub(1912)의 기본기능자체가 -1912 + titanic.age 이런 느낌인 것 같다.
# 따라서 -1912 + 22 = -1890
# -를 풀어주기 위해서 mul(-1)
titanic['YoB'] = titanic.age.sub(1912).mul(-1)titanic.head()
'''
survived pclass sex age sibsp parch fare embarked deck no_relat YoB
0 0 3 male 22.0 1 0 7.2500 S NaN 1 1890.0
1 1 1 female 38.0 1 0 71.2833 C C 1 1874.0
2 1 3 female 26.0 0 0 7.9250 S NaN 0 1886.0
3 1 1 female 35.0 1 0 53.1000 S C 1 1877.0
4 0 3 male 35.0 0 0 8.0500 S NaN 0 1877.0
'''fx_rate = 1.1titanic['EUR_fare'] = titanic.fare.div(fx_rate)titanic.head()
'''
survived pclass sex age sibsp parch fare embarked deck no_relat YoB EUR_fare
0 0 3 male 22.0 1 0 7.2500 S NaN 1 1890.0 6.590909
1 1 1 female 38.0 1 0 71.2833 C C 1 1874.0 64.803000
2 1 3 female 26.0 0 0 7.9250 S NaN 0 1886.0 7.204545
3 1 1 female 35.0 1 0 53.1000 S C 1 1877.0 48.272727
4 0 3 male 35.0 0 0 8.0500 S NaN 0 1877.0 7.318182
'''# 의미 없는 열은 지워줄 것이다.
# sibsp, parch는 no_relat로 만들어 주었기에 의미가 없고
# deck은 너무 결측값이 많아서 의미가 없고
titanic.drop(columns= ['sibsp', 'parch', 'deck', 'YoB', 'EUR_fare'], inplace = True)titanic.head()
'''
survived pclass sex age fare embarked no_relat
0 0 3 male 22.0 7.2500 S 1
1 1 1 female 38.0 71.2833 C 1
2 1 3 female 26.0 7.9250 S 0
3 1 1 female 35.0 53.1000 S 1
4 0 3 male 35.0 8.0500 S 0
'''sales
'''
Mon Tue Wed Thu Fri perc_Bonus Bonus
Steven 34 27 15 NaN 33 0.12 13.08
Mike 45 9 74 87.0 12 0.15 34.05
Andi 17 33 54 8.0 29 0.10 14.10
Paul 87 67 27 45.0 7 0.20 46.60
'''fixed_costs = 5sales.iloc[:,:-2].sub(fixed_costs, fill_value = 0)
'''
Mon Tue Wed Thu Fri
Steven 29 22 10 -5.0 28
Mike 40 4 69 82.0 7
Andi 12 28 49 3.0 24
Paul 82 62 22 40.0 2
'''perc_Bonus = 0.1sales.iloc[:, :-2].mul(perc_Bonus, fill_value = 0)
'''
Mon Tue Wed Thu Fri
Steven 3.4 2.7 1.5 0.0 3.3
Mike 4.5 0.9 7.4 8.7 1.2
Andi 1.7 3.3 5.4 0.8 2.9
Paul 8.7 6.7 2.7 4.5 0.7
'''sales.iloc[:,:-2]
'''
Mon Tue Wed Thu Fri
Steven 34 27 15 NaN 33
Mike 45 9 74 87.0 12
Andi 17 33 54 8.0 29
Paul 87 67 27 45.0 7
'''# 조건 설정
# 10달러 단위로 판매하면 보너스로 1.25달러,
# 10달러 미만으로 판매하면 보너스는 없다.
# 예를들어서 총 판매액이 9달러면 보너스는 없고
# 총 판매액이 17달러면 1.25
# 35달러면 1.25달러 * 3이 되는 것이다.
lot_size = 10
bonus_per_lot = 1.25sales.iloc[:, :-2].floordiv(lot_size, fill_value = 0).mul(bonus_per_lot).sum(axis = 1)
'''
Steven 11.25
Mike 25.00
Andi 13.75
Paul 25.00
dtype: float64
'''## Transformation / Mapping
summer = pd.read_csv('summer.csv')
summer.head()
'''
Year City Sport Discipline Athlete Country Gender Event Medal
0 1896 Athens Aquatics Swimming HAJOS, Alfred HUN Men 100M Freestyle Gold
1 1896 Athens Aquatics Swimming HERSCHMANN, Otto AUT Men 100M Freestyle Silver
2 1896 Athens Aquatics Swimming DRIVAS, Dimitrios GRE Men 100M Freestyle For Sailors Bronze
3 1896 Athens Aquatics Swimming MALOKINIS, Ioannis GRE Men 100M Freestyle For Sailors Gold
4 1896 Athens Aquatics Swimming CHASAPIS, Spiridon GRE Men 100M Freestyle For Sailors Silver
'''# sample 에서 n값은 n만큼 무작위로 함수를 뽑아줘라. 라는 의미고
# 뽑을때마다 값이 달라질 수 있으니, 처음 무작위로 나온 수를 고정해줘라. 라는 의미에서 random_state를 사용해준다고 한다.
# 그런데 random_state의 특이점은 1을 쓰든 123을쓰든 결과적으로 고정해주는건 똑같다고 한다. (이건 불확실)
sample = summer.sample(n = 7, random_state = 123).sort_values(by = 'Year')
'''
Year City Sport Discipline Athlete Country Gender Event Medal
4196 1924 Paris Aquatics Water polo AUSTIN, Arthur USA Men Water Polo Bronze
11961 1968 Mexico Athletics Athletics FOSBURY, Richard Douglas USA Men High Jump Gold
11742 1968 Mexico Aquatics Swimming WENDEN, Michael Vincent AUS Men 200M Freestyle Gold
13996 1976 Montreal Aquatics Swimming MAC DONALD, Gary CAN Men 4X100M Medley Relay Silver
16229 1980 Moscow Rowing Rowing DMITRIENKO, Grigori URS Men Eight With Coxswain (8+) Bronze
19728 1992 Barcelona Aquatics Swimming KULIKOV, Vladislav EUN Men 4X100M Medley Relay Silver
25901 2004 Athens Boxing Boxing YELEUOV, Serik KAZ Men 57 - 60KG (Lightweight) Bronze
'''# sample로 뽑힌 7개의 값이 sample이라는 변수에 저장되어 있고, 이것을 map을 통해서
# 딕셔너리 처리해주고, 키값을 벨류값으로 변경해준다.
sample.City.map(city_country)
'''
4196 France
11961 Mexico
11742 Mexico
13996 Canada
16229 Russia
19728 Spain
25901 Greece
Name: City, dtype: object
'''# 새 컬럼 만들어주기
sample['Host_Country'] = sample.City.map(city_country)sample
'''
Year City Sport Discipline Athlete Country Gender Event Medal Host_Country
4196 1924 Paris Aquatics Water polo AUSTIN, Arthur USA Men Water Polo Bronze France
11961 1968 Mexico Athletics Athletics FOSBURY, Richard Douglas USA Men High Jump Gold Mexico
11742 1968 Mexico Aquatics Swimming WENDEN, Michael Vincent AUS Men 200M Freestyle Gold Mexico
13996 1976 Montreal Aquatics Swimming MAC DONALD, Gary CAN Men 4X100M Medley Relay Silver Canada
16229 1980 Moscow Rowing Rowing DMITRIENKO, Grigori URS Men Eight With Coxswain (8+) Bronze Russia
19728 1992 Barcelona Aquatics Swimming KULIKOV, Vladislav EUN Men 4X100M Medley Relay Silver Spain
25901 2004 Athens Boxing Boxing YELEUOV, Serik KAZ Men 57 - 60KG (Lightweight) Bronze Greece
'''titanic.head()
'''
survived pclass sex age fare embarked no_relat
0 0 3 male 22.0 7.2500 S 1
1 1 1 female 38.0 71.2833 C 1
2 1 3 female 26.0 7.9250 S 0
3 1 1 female 35.0 53.1000 S 1
4 0 3 male 35.0 8.0500 S 0
'''mapper = {1:'First', 2:'Second', 3:'Third'}titanic.pclass.map(mapper)
'''
0 Third
1 First
2 Third
3 First
4 Third
...
886 Second
887 First
888 Third
889 First
890 Third
Name: pclass, Length: 891, dtype: object
'''# 기존의 pclass를 재정의
titanic.pclass = titanic.pclass.map(mapper)titanic.head()
'''
survived pclass sex age fare embarked no_relat
0 0 Third male 22.0 7.2500 S 1
1 1 First female 38.0 71.2833 C 1
2 1 Third female 26.0 7.9250 S 0
3 1 First female 35.0 53.1000 S 1
4 0 Third male 35.0 8.0500 S 0
'''## Conditional Transformation
titanic.head(10)
'''
survived pclass sex age fare embarked no_relat
0 0 Third male 22.0 7.2500 S 1
1 1 First female 38.0 71.2833 C 1
2 1 Third female 26.0 7.9250 S 0
3 1 First female 35.0 53.1000 S 1
4 0 Third male 35.0 8.0500 S 0
5 0 Third male NaN 8.4583 Q 0
6 0 First male 54.0 51.8625 S 0
7 0 Third male 2.0 21.0750 S 4
8 1 Third female 27.0 11.1333 S 2
9 1 Second female 14.0 30.0708 C 1
'''titanic.no_relat == 0import numpy as np
# 이건 일종의 if comprehens다.
# 만약 titanic.no_relat 값이 0이면 'Yes'
# else는 'No'
np.where(titanic.no_relat ==0, 'Yes', 'No')titanic['alone'] = pd.Series(np.where(titanic.no_relat == 0, 'Yes', 'No'))titanic.head()
'''
survived pclass sex age fare embarked no_relat alone
0 0 Third male 22.0 7.2500 S 1 No
1 1 First female 38.0 71.2833 C 1 No
2 1 Third female 26.0 7.9250 S 0 Yes
3 1 First female 35.0 53.1000 S 1 No
4 0 Third male 35.0 8.0500 S 0 Yes
'''titanic['child'] = pd.Series(np.where(titanic.age < 18, 'Yes', 'No'))titanic.head(10)
'''
survived pclass sex age fare embarked no_relat alone child
0 0 Third male 22.0 7.2500 S 1 No No
1 1 First female 38.0 71.2833 C 1 No No
2 1 Third female 26.0 7.9250 S 0 Yes No
3 1 First female 35.0 53.1000 S 1 No No
4 0 Third male 35.0 8.0500 S 0 Yes No
5 0 Third male NaN 8.4583 Q 0 Yes No
6 0 First male 54.0 51.8625 S 0 Yes No
7 0 Third male 2.0 21.0750 S 4 No Yes
8 1 Third female 27.0 11.1333 S 2 No No
9 1 Second female 14.0 30.0708 C 1 No Yes
'''## Discretization and Binning with pd.cut() (Part 1)
- cut은 연속적인 데이터를 특정구간으로 나누어야 할때 사용한다.
- 그리고 이 '특정구간'을 이산화, 구간화 라고 명한다.
titanic.head(10)
'''
survived pclass sex age fare embarked no_relat alone child
0 0 Third male 22.0 7.2500 S 1 No No
1 1 First female 38.0 71.2833 C 1 No No
2 1 Third female 26.0 7.9250 S 0 Yes No
3 1 First female 35.0 53.1000 S 1 No No
4 0 Third male 35.0 8.0500 S 0 Yes No
5 0 Third male NaN 8.4583 Q 0 Yes No
6 0 First male 54.0 51.8625 S 0 Yes No
7 0 Third male 2.0 21.0750 S 4 No Yes
8 1 Third female 27.0 11.1333 S 2 No No
9 1 Second female 14.0 30.0708 C 1 No Yes
'''age_bins = [0,10,18,30,55,100]cats = pd.cut(titanic.age, age_bins, right = False)cats
'''
0 [18.0, 30.0)
1 [30.0, 55.0)
2 [18.0, 30.0)
3 [30.0, 55.0)
4 [30.0, 55.0)
...
886 [18.0, 30.0)
887 [18.0, 30.0)
888 NaN
889 [18.0, 30.0)
890 [30.0, 55.0)
Name: age, Length: 891, dtype: category
Categories (5, interval[int64, left]): [[0, 10) < [10, 18) < [18, 30) < [30, 55) < [55, 100)]
'''cats.value_counts()
'''
[30, 55) 288
[18, 30) 271
[0, 10) 62
[10, 18) 51
[55, 100) 42
Name: age, dtype: int64
'''titanic['age_cat'] = catstitanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat
0 0 Third male 22.0 7.2500 S 1 No No [18, 30)
1 1 First female 38.0 71.2833 C 1 No No [30, 55)
2 1 Third female 26.0 7.9250 S 0 Yes No [18, 30)
3 1 First female 35.0 53.1000 S 1 No No [30, 55)
4 0 Third male 35.0 8.0500 S 0 Yes No [30, 55)
'''titanic.groupby('age_cat').survived.mean()
'''
age_cat
[0, 10) 0.612903
[10, 18) 0.450980
[18, 30) 0.350554
[30, 55) 0.420139
[55, 100) 0.309524
Name: survived, dtype: float64
'''group_names = ['child', 'teenager', 'young_adult', 'adult', 'elderly']pd.cut(titanic.age, age_bins, right = False, labels = group_names)
'''
0 young_adult
1 adult
2 young_adult
3 adult
4 adult
...
886 young_adult
887 young_adult
888 NaN
889 young_adult
890 adult
Name: age, Length: 891, dtype: category
Categories (5, object): ['child' < 'teenager' < 'young_adult' < 'adult' < 'elderly']
'''titanic['age_cat'] = pd.cut(titanic.age, age_bins, right = False, labels = group_names)titanic.head(10)
'''
survived pclass sex age fare embarked no_relat alone child age_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult
1 1 First female 38.0 71.2833 C 1 No No adult
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult
3 1 First female 35.0 53.1000 S 1 No No adult
4 0 Third male 35.0 8.0500 S 0 Yes No adult
5 0 Third male NaN 8.4583 Q 0 Yes No NaN
6 0 First male 54.0 51.8625 S 0 Yes No adult
7 0 Third male 2.0 21.0750 S 4 No Yes child
8 1 Third female 27.0 11.1333 S 2 No No young_adult
9 1 Second female 14.0 30.0708 C 1 No Yes teenager
'''titanic.age_cat
'''
0 young_adult
1 adult
2 young_adult
3 adult
4 adult
...
886 young_adult
887 young_adult
888 NaN
889 young_adult
890 adult
Name: age_cat, Length: 891, dtype: category
Categories (5, object): ['child' < 'teenager' < 'young_adult' < 'adult' < 'elderly']
'''## Discretization and Binning with pd.cut() (Part 2)
- Discretization는 '이산화', 그룹을 나눈다는 뜻titanic.fare
'''
0 7.2500
1 71.2833
2 7.9250
3 53.1000
4 8.0500
...
886 13.0000
887 30.0000
888 23.4500
889 30.0000
890 7.7500
Name: fare, Length: 891, dtype: float64
'''# 구간 나누기 함수 cut
# titanic.fare를
# 5개의 구간으로 나누어 줘
# 소수점 자리는 0. 즉, 실질적 int로 사용할래
# precision의 기본값은 3으로써 소수점 아래 3자리까지 나오는 것이 기본이다.
pd.cut(titanic.fare, 5, precision = 0)
'''
0 (-1.0, 102.0]
1 (-1.0, 102.0]
2 (-1.0, 102.0]
3 (-1.0, 102.0]
4 (-1.0, 102.0]
...
886 (-1.0, 102.0]
887 (-1.0, 102.0]
888 (-1.0, 102.0]
889 (-1.0, 102.0]
890 (-1.0, 102.0]
Name: fare, Length: 891, dtype: category
Categories (5, interval[float64, right]): [(-1.0, 102.0] < (102.0, 205.0] < (205.0, 307.0] < (307.0, 410.0] < (410.0, 512.0]]
'''titanic['fare_cat'] = pd.cut(titanic.fare, 5, precision = 0)titanic.head(10)
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult (-1.0, 102.0]
1 1 First female 38.0 71.2833 C 1 No No adult (-1.0, 102.0]
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult (-1.0, 102.0]
3 1 First female 35.0 53.1000 S 1 No No adult (-1.0, 102.0]
4 0 Third male 35.0 8.0500 S 0 Yes No adult (-1.0, 102.0]
5 0 Third male NaN 8.4583 Q 0 Yes No NaN (-1.0, 102.0]
6 0 First male 54.0 51.8625 S 0 Yes No adult (-1.0, 102.0]
7 0 Third male 2.0 21.0750 S 4 No Yes child (-1.0, 102.0]
8 1 Third female 27.0 11.1333 S 2 No No young_adult (-1.0, 102.0]
9 1 Second female 14.0 30.0708 C 1 No Yes teenager (-1.0, 102.0]
'''titanic.fare_cat.value_counts()
'''
(-1.0, 102.0] 838
(102.0, 205.0] 33
(205.0, 307.0] 17
(410.0, 512.0] 3
(307.0, 410.0] 0
Name: fare_cat, dtype: int64
'''
# 307~ 410을 보면 count가 0이다.
# 이럴때 사용해 주는 것이 pd.qcut이다.## Discretization and Binning with pd.qcut()
titanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult (-1.0, 102.0]
1 1 First female 38.0 71.2833 C 1 No No adult (-1.0, 102.0]
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult (-1.0, 102.0]
3 1 First female 35.0 53.1000 S 1 No No adult (-1.0, 102.0]
4 0 Third male 35.0 8.0500 S 0 Yes No adult (-1.0, 102.0]
'''pd.qcut(titanic.fare, 5)
'''
0 (-0.001, 7.854]
1 (39.688, 512.329]
2 (7.854, 10.5]
3 (39.688, 512.329]
4 (7.854, 10.5]
...
886 (10.5, 21.679]
887 (21.679, 39.688]
888 (21.679, 39.688]
889 (21.679, 39.688]
890 (-0.001, 7.854]
Name: fare, Length: 891, dtype: category
Categories (5, interval[float64, right]): [(-0.001, 7.854] < (7.854, 10.5] < (10.5, 21.679] < (21.679, 39.688] < (39.688, 512.329]]
'''titanic['fare_cat'] = pd.qcut(titanic.fare, 5)titanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult (-0.001, 7.854]
1 1 First female 38.0 71.2833 C 1 No No adult (39.688, 512.329]
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult (7.854, 10.5]
3 1 First female 35.0 53.1000 S 1 No No adult (39.688, 512.329]
4 0 Third male 35.0 8.0500 S 0 Yes No adult (7.854, 10.5]
'''# 값이 5구간으로 잘 나누어져 있는지 확인
titanic.fare_cat.value_counts()
'''
(7.854, 10.5] 184
(21.679, 39.688] 180
(-0.001, 7.854] 179
(39.688, 512.329] 176
(10.5, 21.679] 172
Name: fare_cat, dtype: int64
'''
# 얼추 5구간으로 나누어져있으며, 이 값은 계수값이 많아질수록 정확해진다.pd.qcut(titanic.fare, [0, 0.1, 0.25, 0.5, 0.9, 1], precision = 0)
'''
0 (-0.1, 7.6]
1 (14.5, 78.0]
2 (7.9, 14.5]
3 (14.5, 78.0]
4 (7.9, 14.5]
...
886 (7.9, 14.5]
887 (14.5, 78.0]
888 (14.5, 78.0]
889 (14.5, 78.0]
890 (7.6, 7.9]
Name: fare, Length: 891, dtype: category
Categories (5, interval[float64, right]): [(-0.1, 7.6] < (7.6, 7.9] < (7.9, 14.5] < (14.5, 78.0] < (78.0, 512.3]]
'''titanic['fare_cat'] = pd.qcut(titanic.fare, [0, 0.1, 0.25, 0.5, 0.9, 1], precision = 0)titanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult (-0.1, 7.6]
1 1 First female 38.0 71.2833 C 1 No No adult (14.5, 78.0]
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult (7.9, 14.5]
3 1 First female 35.0 53.1000 S 1 No No adult (14.5, 78.0]
4 0 Third male 35.0 8.0500 S 0 Yes No adult (7.9, 14.5]
'''titanic.fare_cat.value_counts()
'''
(14.5, 78.0] 357
(7.9, 14.5] 224
(7.6, 7.9] 131
(-0.1, 7.6] 92
(78.0, 512.3] 87
Name: fare_cat, dtype: int64
'''fare_labels = ['very_cheap', 'cheap', 'moderate', 'exp', 'very_exp']titanic.groupby(['age_cat', 'fare_cat']).survived.mean().unstack()
'''
fare_cat (-0.1, 7.6] (7.6, 7.9] (7.9, 14.5] (14.5, 78.0] (78.0, 512.3]
age_cat
child NaN NaN 0.875000 0.568627 0.666667
teenager 0.333333 0.500000 0.500000 0.263158 1.000000
young_adult 0.258065 0.222222 0.244444 0.533333 0.619048
adult 0.000000 0.050000 0.320513 0.488000 0.809524
elderly 0.000000 0.000000 0.250000 0.272727 0.714286
''' titanic['fare_cat'] = pd.qcut(titanic.fare, [0,0.1,0.25,0.5,0.9,1], precision = 0, labels = fare_labels)titanic.head(10)
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult very_cheap
1 1 First female 38.0 71.2833 C 1 No No adult exp
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult moderate
3 1 First female 35.0 53.1000 S 1 No No adult exp
4 0 Third male 35.0 8.0500 S 0 Yes No adult moderate
5 0 Third male NaN 8.4583 Q 0 Yes No NaN moderate
6 0 First male 54.0 51.8625 S 0 Yes No adult exp
7 0 Third male 2.0 21.0750 S 4 No Yes child exp
8 1 Third female 27.0 11.1333 S 2 No No young_adult moderate
9 1 Second female 14.0 30.0708 C 1 No Yes teenager exp
'''## Caps and Floors
# cap과 floor를 이용해서 수치형 열에 상한값과 하한값을 설정하여서
# 아웃라이어를 제거할것이다.
titanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult very_cheap
1 1 First female 38.0 71.2833 C 1 No No adult exp
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult moderate
3 1 First female 35.0 53.1000 S 1 No No adult exp
4 0 Third male 35.0 8.0500 S 0 Yes No adult moderate
1
'''import matplotlib.pyplot as plt
titanic.fare.plot(figsize = (14,10))
plt.show()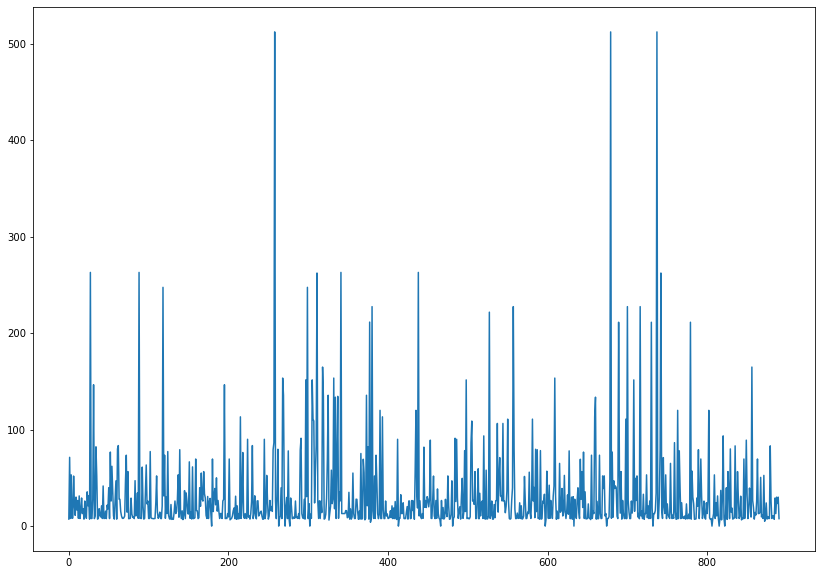
titanic.fare.describe()
'''
count 891.000000
mean 32.204208
std 49.693429
min 0.000000
25% 7.910400
50% 14.454200
75% 31.000000
max 512.329200
Name: fare, dtype: float64
'''titanic.fare.sort_values(ascending= False)
'''
258 512.3292
737 512.3292
679 512.3292
88 263.0000
27 263.0000
...
633 0.0000
413 0.0000
822 0.0000
732 0.0000
674 0.0000
Name: fare, Length: 891, dtype: float64
'''fare_cap = 250# titanic의 fare 컬럼 중에서 fare_cap에 설정된 값보다 더 크면
# fare 컬럼의 해당 값을
# fare_cap으로 전환해준다.
titanic.loc[titanic.fare > fare_cap, 'fare'] = fare_capfare_floor = 5
# titanic의 fare 컬럼이 fare_floor 보다 작으면
# 해당 fare컬럼의 필드값을
# fare_floor로 전환해준다.
titanic.loc[titanic.fare < fare_floor, 'fare'] = fare_floortitanic.fare.plot(figsize = (14,10))
plt.show()
# 기존에는 500이 넘는 값도 있었는데 250에서 끊어진다.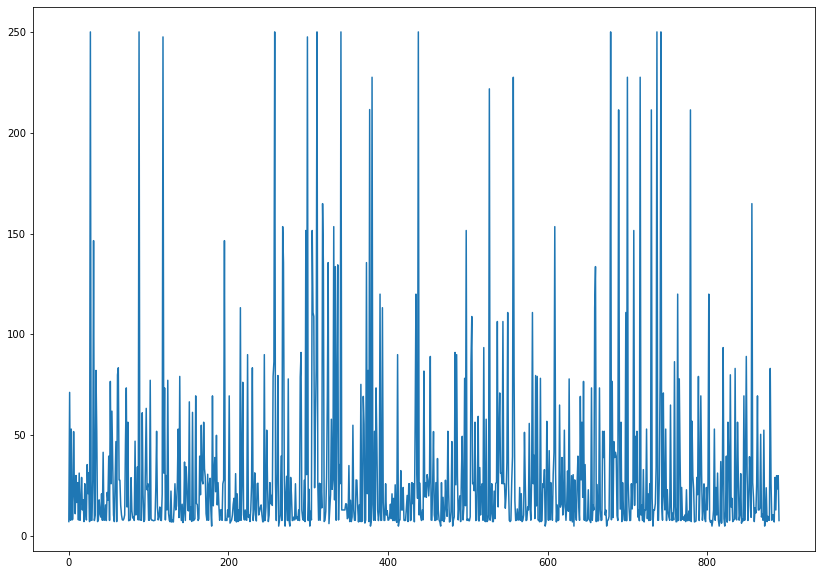
titanic.fare.describe()
'''
count 891.000000
mean 31.320089
std 42.517981
min 5.000000
25% 7.910400
50% 14.454200
75% 31.000000
max 250.000000
Name: fare, dtype: float64
'''# 최소값, 최대값 확인하기
titanic.fare.sort_values(ascending=False)
'''
258 250.0
88 250.0
311 250.0
27 250.0
341 250.0
...
413 5.0
822 5.0
872 5.0
732 5.0
674 5.0
Name: fare, Length: 891, dtype: float64
'''## Scaling / Standardization
- 머신러닝이나 통계분석에 사용되는 알고리즘들은 스케일에 매우 민감한 특성이 있다.
titanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat
0 0 Third male 22.0 7.2500 S 1 No No young_adult very_cheap
1 1 First female 38.0 71.2833 C 1 No No adult exp
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult moderate
3 1 First female 35.0 53.1000 S 1 No No adult exp
4 0 Third male 35.0 8.0500 S 0 Yes No adult moderate
'''titanic.describe()
'''
survived age fare no_relat
count 891.000000 714.000000 891.000000 891.000000
mean 0.383838 29.699118 31.320089 0.904602
std 0.486592 14.526497 42.517981 1.613459
min 0.000000 0.420000 5.000000 0.000000
25% 0.000000 20.125000 7.910400 0.000000
50% 0.000000 28.000000 14.454200 0.000000
75% 1.000000 38.000000 31.000000 1.000000
max 1.000000 80.000000 250.000000 10.000000
'''import matplotlib.pyplot as plt
titanic.fare.plot(figsize = (14,10))
titanic.age.plot(figsize = (14,10))
plt.show()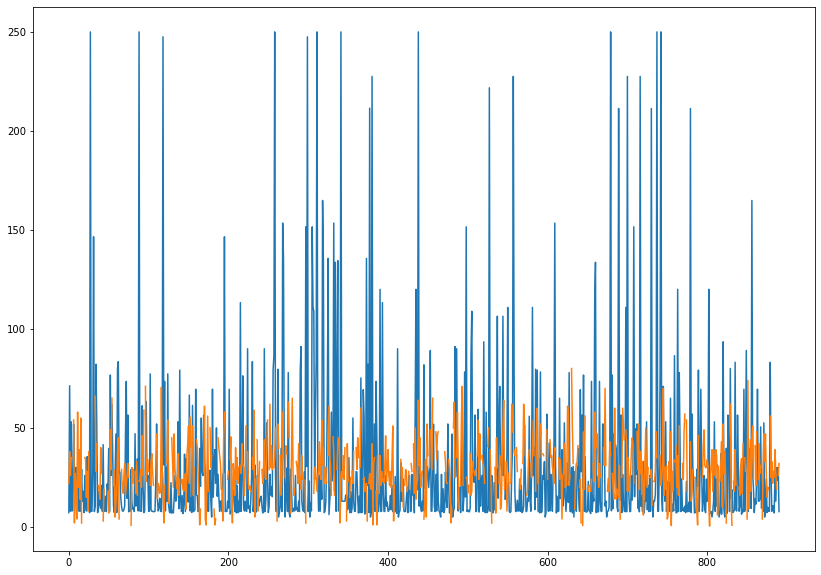
mean_age = titanic.age.mean()
mean_fare = titanic.fare.mean()std_age = titanic.age.std()
std_fare = titanic.fare.std()titanic['age_z'] = (titanic.age-mean_age) / std_age
titanic['fare_z'] = (titanic.fare-mean_fare) / std_faretitanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat age_z fare_z
0 0 Third male 22.0 7.2500 S 1 No No young_adult very_cheap -0.530005 -0.566116
1 1 First female 38.0 71.2833 C 1 No No adult exp 0.571430 0.939913
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult moderate -0.254646 -0.550240
3 1 First female 35.0 53.1000 S 1 No No adult exp 0.364911 0.512252
4 0 Third male 35.0 8.0500 S 0 Yes No adult moderate 0.364911 -0.547300
'''round(titanic.describe(), 2)
'''
survived age fare no_relat age_z fare_z
count 891.00 714.00 891.00 891.00 714.00 891.00
mean 0.38 29.70 31.32 0.90 0.00 0.00
std 0.49 14.53 42.52 1.61 1.00 1.00
min 0.00 0.42 5.00 0.00 -2.02 -0.62
25% 0.00 20.12 7.91 0.00 -0.66 -0.55
50% 0.00 28.00 14.45 0.00 -0.12 -0.40
75% 1.00 38.00 31.00 1.00 0.57 -0.01
max 1.00 80.00 250.00 10.00 3.46 5.14
'''titanic.fare_z.plot(figsize = (14,10))
titanic.age_z.plot(figsize = (14,10))
plt.show()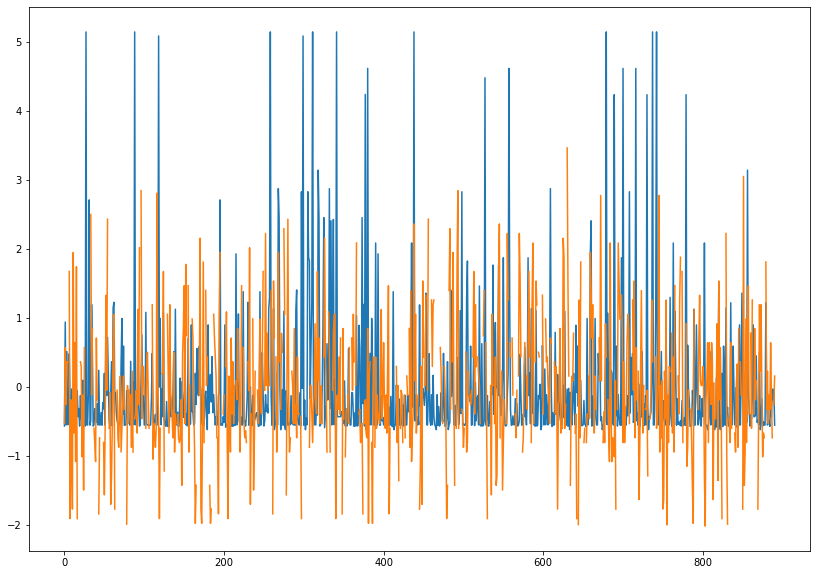
## Creating Dummy Variables
titanic.head()
'''
survived pclass sex age fare embarked no_relat alone child age_cat fare_cat age_z fare_z
0 0 Third male 22.0 7.2500 S 1 No No young_adult very_cheap -0.530005 -0.566116
1 1 First female 38.0 71.2833 C 1 No No adult exp 0.571430 0.939913
2 1 Third female 26.0 7.9250 S 0 Yes No young_adult moderate -0.254646 -0.550240
3 1 First female 35.0 53.1000 S 1 No No adult exp 0.364911 0.512252
4 0 Third male 35.0 8.0500 S 0 Yes No adult moderate 0.364911 -0.547300
'''titanic.drop(labels = ['age', 'alone', 'child', 'age_z', 'fare_z', 'fare_cat'], axis = 1, inplace = True)titanic.head()
'''
survived pclass sex fare embarked no_relat age_cat
0 0 Third male 7.2500 S 1 young_adult
1 1 First female 71.2833 C 1 adult
2 1 Third female 7.9250 S 0 young_adult
3 1 First female 53.1000 S 1 adult
4 0 Third male 8.0500 S 0 adult
'''# 리스트화를 빼고 했을때 type 에러가 난다.
# pd.get_dummies(titanic, columns = 'sex')
# TypeError: Input must be a list-like for parameter `columns`
# 올바른 코드
pd.get_dummies(titanic, columns = ['sex'])
'''
survived pclass fare embarked no_relat age_cat sex_female sex_male
0 0 Third 7.2500 S 1 young_adult 0 1
1 1 First 71.2833 C 1 adult 1 0
2 1 Third 7.9250 S 0 young_adult 1 0
3 1 First 53.1000 S 1 adult 1 0
4 0 Third 8.0500 S 0 adult 0 1
... ... ... ... ... ... ... ... ...
886 0 Second 13.0000 S 0 young_adult 0 1
887 1 First 30.0000 S 0 young_adult 1 0
888 0 Third 23.4500 S 3 NaN 1 0
889 1 First 30.0000 C 0 young_adult 0 1
890 0 Third 7.7500 Q 0 adult 0 1
891 rows × 8 columns
'''# 원 핫 인코딩?
pd.get_dummies(titanic, columns = ['sex', 'pclass'])
'''
survived fare embarked no_relat age_cat sex_female sex_male pclass_First pclass_Second pclass_Third
0 0 7.2500 S 1 young_adult 0 1 0 0 1
1 1 71.2833 C 1 adult 1 0 1 0 0
2 1 7.9250 S 0 young_adult 1 0 0 0 1
3 1 53.1000 S 1 adult 1 0 1 0 0
4 0 8.0500 S 0 adult 0 1 0 0 1
... ... ... ... ... ... ... ... ... ... ...
886 0 13.0000 S 0 young_adult 0 1 0 1 0
887 1 30.0000 S 0 young_adult 1 0 1 0 0
888 0 23.4500 S 3 NaN 1 0 0 0 1
889 1 30.0000 C 0 young_adult 0 1 1 0 0
890 0 7.7500 Q 0 adult 0 1 0 0 1
891 rows × 10 columns
'''pd.get_dummies(titanic, columns = ['sex', 'pclass'], drop_first = True)
'''
survived fare embarked no_relat age_cat sex_male pclass_Second pclass_Third
0 0 7.2500 S 1 young_adult 1 0 1
1 1 71.2833 C 1 adult 0 0 0
2 1 7.9250 S 0 young_adult 0 0 1
3 1 53.1000 S 1 adult 0 0 0
4 0 8.0500 S 0 adult 1 0 1
... ... ... ... ... ... ... ... ...
886 0 13.0000 S 0 young_adult 1 1 0
887 1 30.0000 S 0 young_adult 0 0 0
888 0 23.4500 S 3 NaN 0 0 1
889 1 30.0000 C 0 young_adult 1 0 0
890 0 7.7500 Q 0 adult 1 0 1
891 rows × 8 columns
'''titanic_d = pd.get_dummies(titanic, columns = ['sex', 'pclass', 'embarked', 'age_cat'], drop_first = True)
'''
survived fare no_relat sex_male pclass_Second pclass_Third embarked_Q embarked_S age_cat_teenager age_cat_young_adult age_cat_adult age_cat_elderly
0 0 7.2500 1 1 0 1 0 1 0 1 0 0
1 1 71.2833 1 0 0 0 0 0 0 0 1 0
2 1 7.9250 0 0 0 1 0 1 0 1 0 0
3 1 53.1000 1 0 0 0 0 1 0 0 1 0
4 0 8.0500 0 1 0 1 0 1 0 0 1 0
... ... ... ... ... ... ... ... ... ... ... ... ...
886 0 13.0000 0 1 1 0 0 1 0 1 0 0
887 1 30.0000 0 0 0 0 0 1 0 1 0 0
888 0 23.4500 3 0 0 1 0 1 0 0 0 0
889 1 30.0000 0 1 0 0 0 0 0 1 0 0
890 0 7.7500 0 1 0 1 1 0 0 0 1 0
891 rows × 12 columns
'''titanic_d.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 fare 891 non-null float64
2 no_relat 891 non-null int64
3 sex_male 891 non-null uint8
4 pclass_Second 891 non-null uint8
5 pclass_Third 891 non-null uint8
6 embarked_Q 891 non-null uint8
7 embarked_S 891 non-null uint8
8 age_cat_teenager 891 non-null uint8
9 age_cat_young_adult 891 non-null uint8
10 age_cat_adult 891 non-null uint8
11 age_cat_elderly 891 non-null uint8
dtypes: float64(1), int64(2), uint8(9)
memory usage: 28.8 KB
'''## String Operations
- 데이터 클리닝
- 중요 파트
import pandas as pd
summer = pd.read_csv('summer.csv')
summer.head()
'''
Year City Sport Discipline Athlete Country Gender Event Medal
0 1896 Athens Aquatics Swimming HAJOS, Alfred HUN Men 100M Freestyle Gold
1 1896 Athens Aquatics Swimming HERSCHMANN, Otto AUT Men 100M Freestyle Silver
2 1896 Athens Aquatics Swimming DRIVAS, Dimitrios GRE Men 100M Freestyle For Sailors Bronze
3 1896 Athens Aquatics Swimming MALOKINIS, Ioannis GRE Men 100M Freestyle For Sailors Gold
4 1896 Athens Aquatics Swimming CHASAPIS, Spiridon GRE Men 100M Freestyle For Sailors Silver
'''# Athlete의 필드들을 보면 HAJOS, Alfred 이렇게 공백과 컴머가 있다.
# 이것들을 기준으로 분리를 해준다.
summer.Athlete.str.split(', ', n = 1, expand = True)
'''
0 1
0 HAJOS Alfred
1 HERSCHMANN Otto
2 DRIVAS Dimitrios
3 MALOKINIS Ioannis
4 CHASAPIS Spiridon
... ... ...
31160 JANIKOWSKI Damian
31161 REZAEI Ghasem Gholamreza
31162 TOTROV Rustam
31163 ALEKSANYAN Artur
31164 LIDBERG Jimmy
31165 rows × 2 columns
'''summer[['Surname', 'First_Name']] = summer.Athlete.str.split(', ', n = 1, expand = True)summer.head()
'''
Year City Sport Discipline Athlete Country Gender Event Medal Surname First_Name
0 1896 Athens Aquatics Swimming HAJOS, Alfred HUN Men 100M Freestyle Gold HAJOS Alfred
1 1896 Athens Aquatics Swimming HERSCHMANN, Otto AUT Men 100M Freestyle Silver HERSCHMANN Otto
2 1896 Athens Aquatics Swimming DRIVAS, Dimitrios GRE Men 100M Freestyle For Sailors Bronze DRIVAS Dimitrios
3 1896 Athens Aquatics Swimming MALOKINIS, Ioannis GRE Men 100M Freestyle For Sailors Gold MALOKINIS Ioannis
4 1896 Athens Aquatics Swimming CHASAPIS, Spiridon GRE Men 100M Freestyle For Sailors Silver CHASAPIS Spiridon
'''summer['Surname'] = summer.Surname.str.strip()summer['First_Name'] = summer.First_Name.str.strip()summer.head()
'''
Year City Sport Discipline Athlete Country Gender Event Medal Surname First_Name
0 1896 Athens Aquatics Swimming HAJOS, Alfred HUN Men 100M Freestyle Gold HAJOS Alfred
1 1896 Athens Aquatics Swimming HERSCHMANN, Otto AUT Men 100M Freestyle Silver HERSCHMANN Otto
2 1896 Athens Aquatics Swimming DRIVAS, Dimitrios GRE Men 100M Freestyle For Sailors Bronze DRIVAS Dimitrios
3 1896 Athens Aquatics Swimming MALOKINIS, Ioannis GRE Men 100M Freestyle For Sailors Gold MALOKINIS Ioannis
4 1896 Athens Aquatics Swimming CHASAPIS, Spiridon GRE Men 100M Freestyle For Sailors Silver CHASAPIS Spiridon
'''summer.drop(columns = 'Athlete')
오... 이번 섹션도 진짜 어려웠다....
보면 알겠는데 활용을 진짜 못하겠다... 아직은
300x250
'개발일지 > 임시카테고리' 카테고리의 다른 글
| (해결)과제 1 postgresql 슬로우 쿼리 해결방법 찾기 (0) | 2022.08.18 |
|---|---|
| SQL 기초 1 DISTINCT, COUNT (0) | 2022.08.18 |
| SQL 문자형 함수, 숫자형 함수, 날짜형 함수, 변환형 함수 (0) | 2022.08.16 |
| pandas 판다스 틀린문제 10 crosstab, pivot_table (0) | 2022.08.15 |
| pandas 판다스 기초 20, crosstab, melt, pivot_table (0) | 2022.08.15 |