320x100
간만에 좀 수월한 진행이였다.
# Advanced / statistical plotting with seaborn
## First Steps
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
titanic = pd.read_csv('titanic.csv')
titanic.head()
'''
survived pclass sex age sibsp parch fare embarked deck
0 0 3 male 22.0 1 0 7.2500 S NaN
1 1 1 female 38.0 1 0 71.2833 C C
2 1 3 female 26.0 0 0 7.9250 S NaN
3 1 1 female 35.0 1 0 53.1000 S C
4 0 3 male 35.0 0 0 8.0500 S NaN
'''# 카운트 플롯
plt.figure(figsize = (14,10))
sns.countplot(data = titanic, x = 'sex')
plt.show()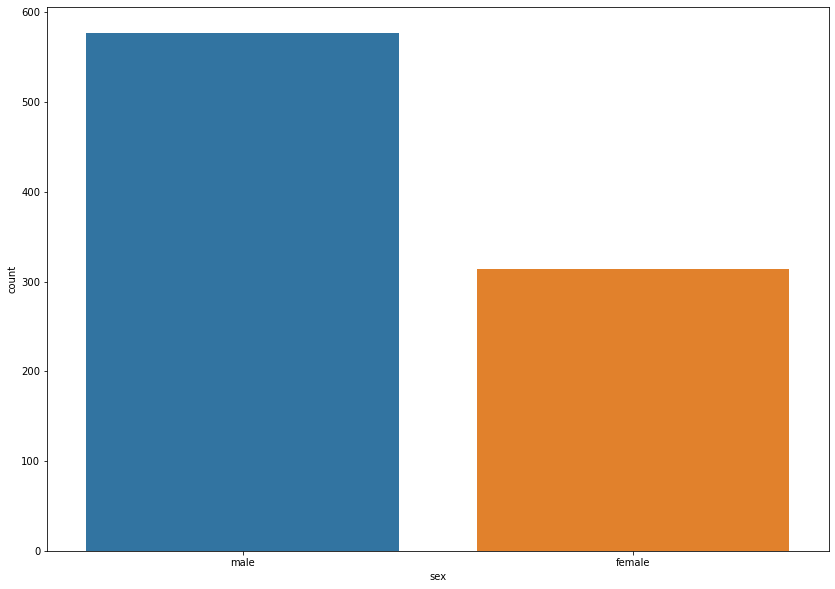
# 범주형 데이터 지정시, hue를 이용해준다.
# 범주형 데이터는 범위를 가진 데이터로써, 1등급, 2등급 뭐 그런 개념을 생각하면 된다.
plt.figure(figsize = (14,10))
sns.countplot(data = titanic, x = 'sex', hue = 'pclass')
plt.show()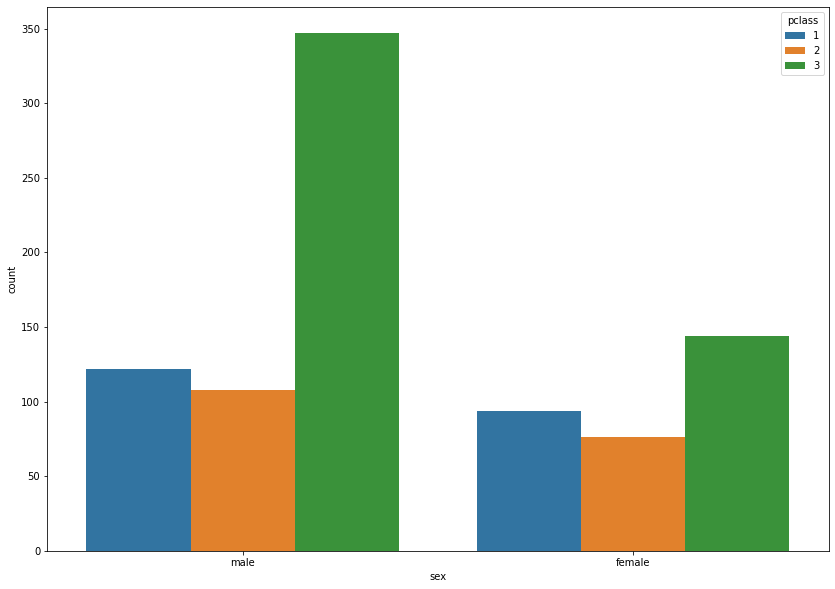
# set은 미적 매개변수로써, 생김새를 다르게 할 수 있다.
plt.figure(figsize = (14,10))
sns.set(font_scale = 2, palette = 'viridis')
sns.countplot(data = titanic, x = 'sex', hue = 'pclass')
plt.show()
# sns.set의 palette로 더 많은 색상 커스텀을 원한다면 matplotlib 사이트를 참조하도록 하자.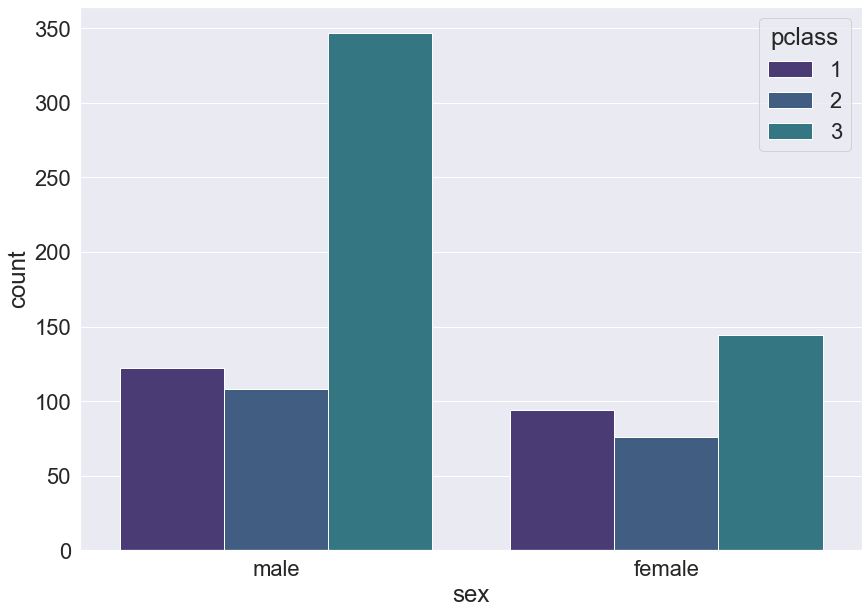
## Categorical Plots
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.4)
sns.stripplot(data = titanic, x = 'sex', y = 'age', jitter = False, hue = None, dodge = False)
plt.show()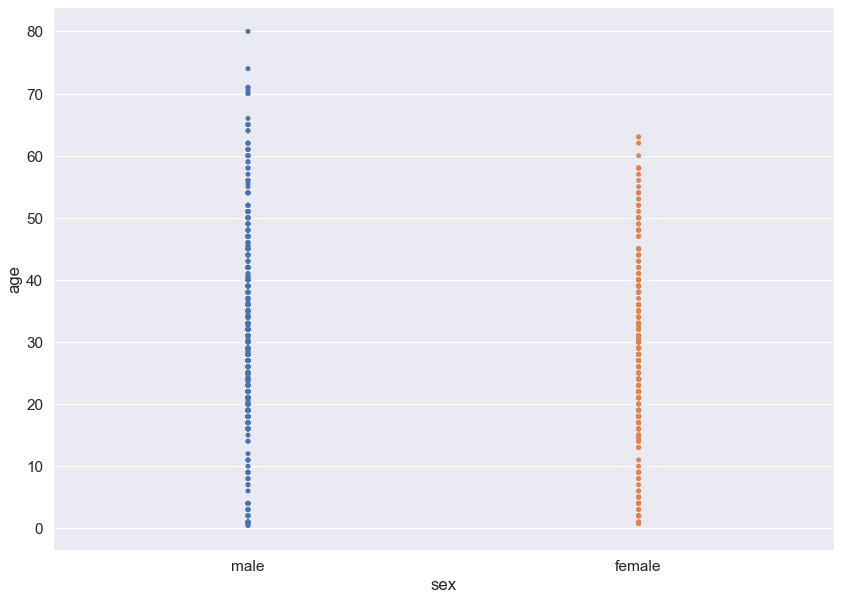
# swarmplot은 분포정도를 가장 쉽게 확인할 수 있다.
# 밀집되어있는 부분은 옆으로 튀어나오기 때문이다.
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.5)
sns.swarmplot(data = titanic, x = 'sex', y = 'age', hue = 'pclass', dodge = True)
plt.show()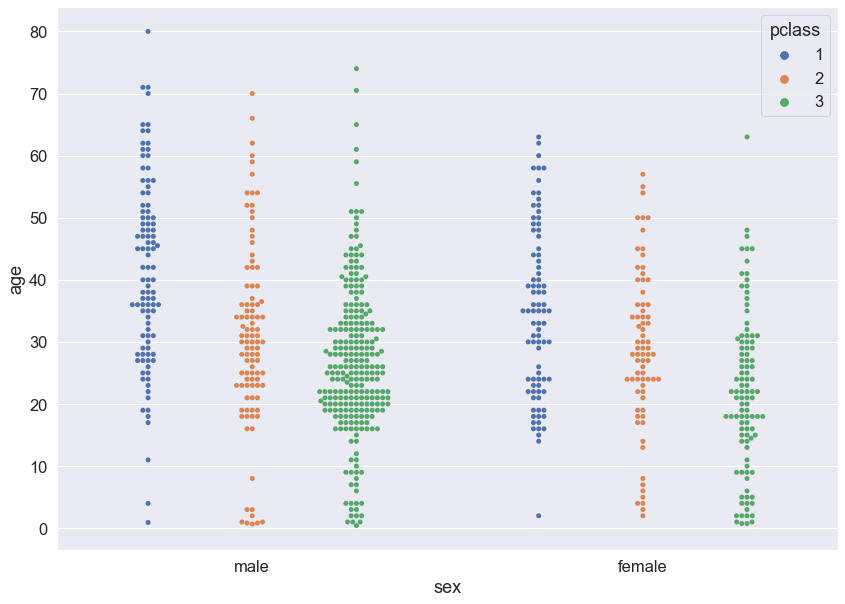
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.5)
sns.violinplot(data = titanic, x = 'sex', y = 'age', hue = 'pclass', dodge = True)
plt.show()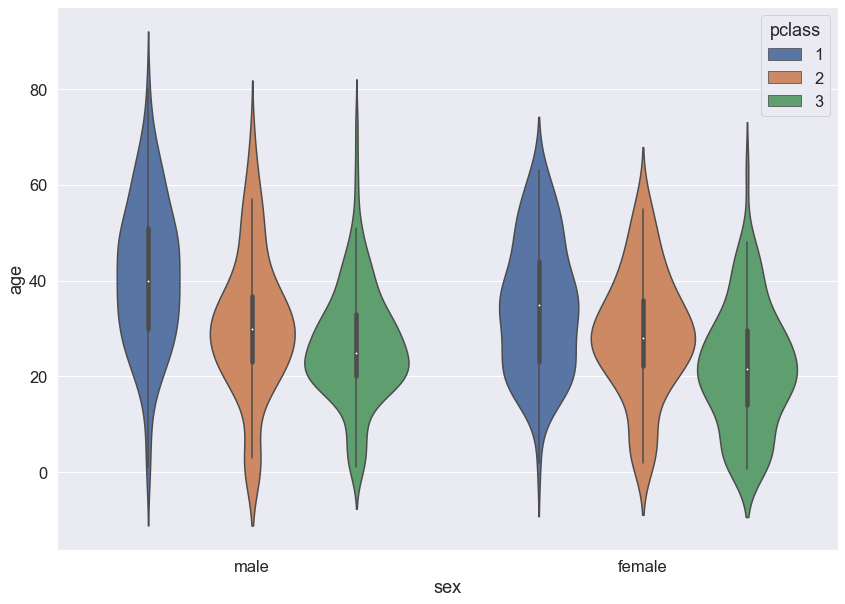
# violinplot, swarmplot은 함께 사용이 가능하다.
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.4)
sns.violinplot(data = titanic, x = 'sex', y = 'age', hue = 'pclass', dodge = True)
sns.swarmplot(data = titanic, x = 'sex', y = 'age', hue = 'pclass', dodge = True, color = 'black')
plt.show()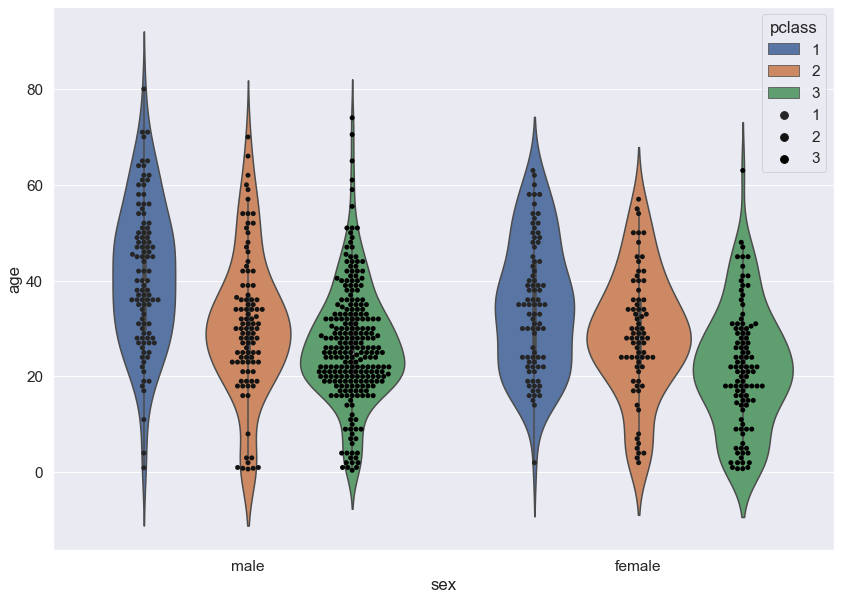
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.5)
sns.violinplot(data = titanic, x = 'pclass', y = 'age', hue = 'sex', dodge = True, split = False)
plt.show()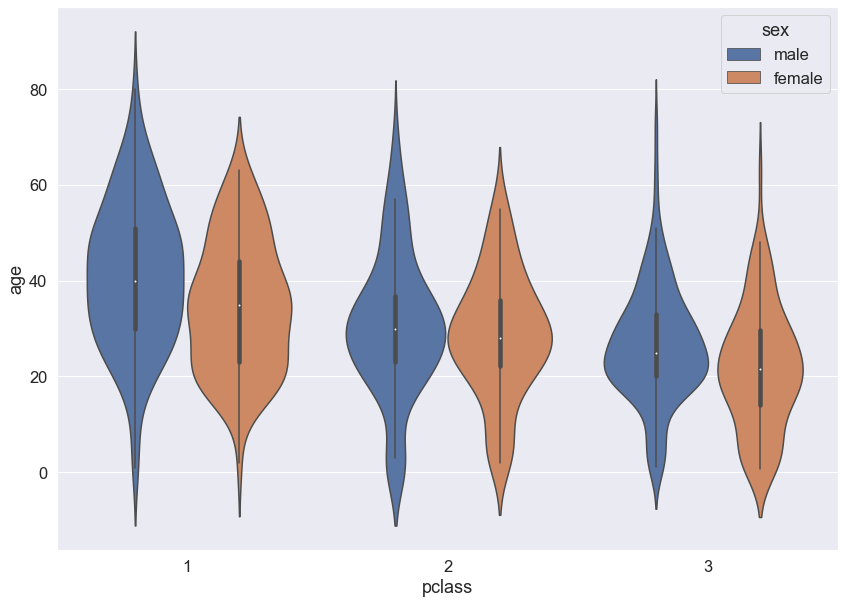
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.5)
sns.barplot(data = titanic, x = 'pclass', y = 'age', hue = 'sex', dodge = True)
plt.show()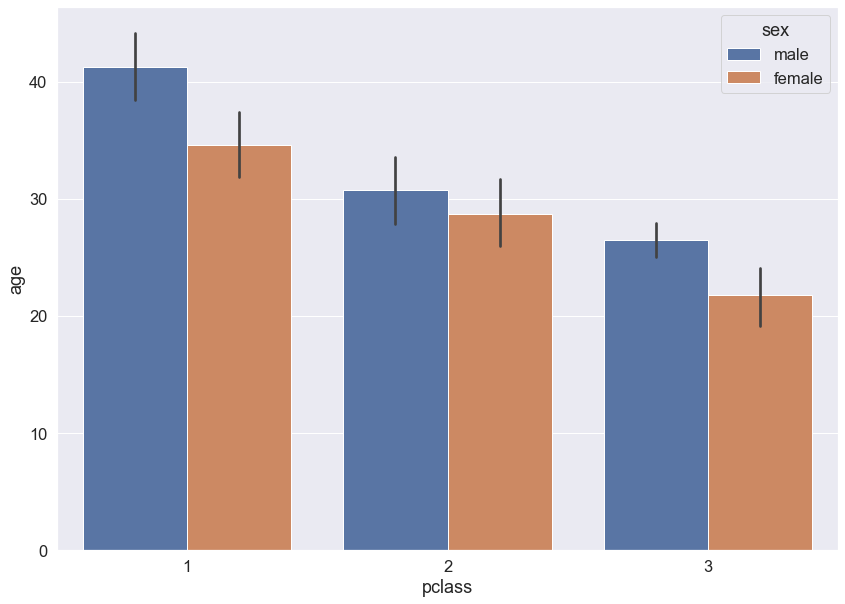
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.4)
sns.pointplot(data = titanic, x = 'pclass', y = 'age', hue = 'sex', dodge = True)
plt.show()
# 각 x 축의 값마다 y축의 중간값으로 잡히는 것이 해당 x 값의 평균이다.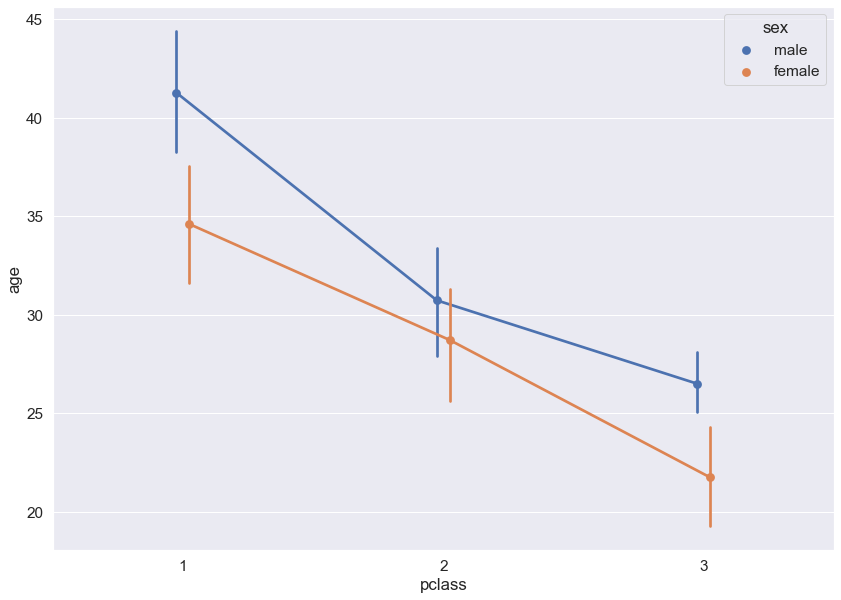
## Jointplots / Regression
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
titanic = pd.read_csv('titanic.csv')
titanic.head()
'''
survived pclass sex age sibsp parch fare embarked deck
0 0 3 male 22.0 1 0 7.2500 S NaN
1 1 1 female 38.0 1 0 71.2833 C C
2 1 3 female 26.0 0 0 7.9250 S NaN
3 1 1 female 35.0 1 0 53.1000 S C
4 0 3 male 35.0 0 0 8.0500 S NaN
'''# 산점도
# 나이와 승선 요금에 관해서 어떤 상관관계가 있는지 확인하고 싶다.
# 그럴때 사용하는 것이 '회귀 플롯 형식'이며, kind = 'reg' 로써 활용이 가능하다.
sns.set(font_scale = 1.5)
sns.jointplot(data = titanic, x = 'age', y = 'fare', height = 8, kind = 'reg' )
plt.show()
# 선이 약간씩 올라가는 모습을 보인다.
# 이럴 경우 '긍정적인'양의 상관관계에 있다는 것을 알 수 있다.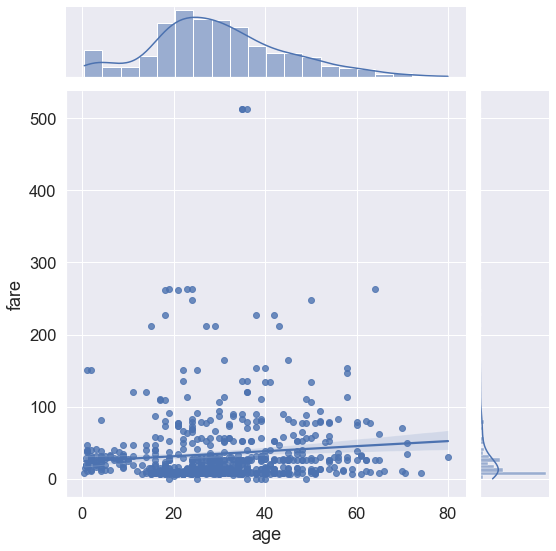
# 상관관계를 회귀방법으로 확인하는 것은 kind = 'reg'로도 가능하지만
# lmplot으로도 가능하다.
# aspect와 height는 그래프의 사이즈를 의미한다.
# hue에 무엇을 넣느냐에 따라서 구분이 가능해진다 (일반적으로 데이터 프레임의 컬럼값을 넣는다고 보면 된다.)
sns.set(font_scale = 1.5)
sns.lmplot(data = titanic, x = 'age', y = 'fare', aspect = 1, height = 8, hue ='sex')
plt.show()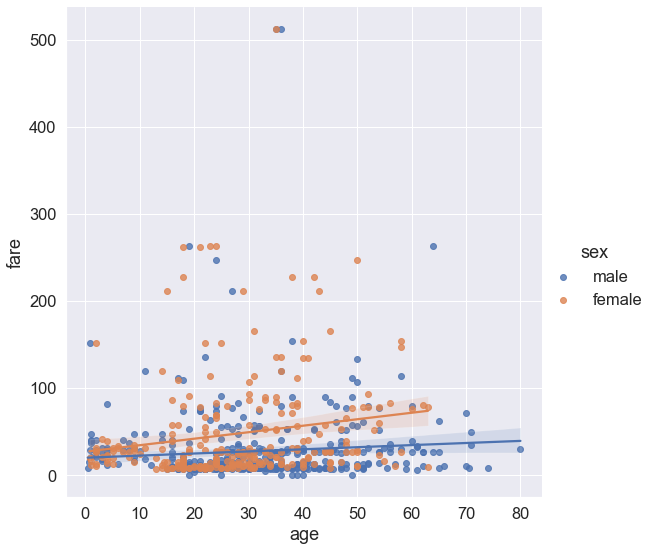
# 비교할때, 위의 방법처럼 하나로 합쳐서 보는 방법도 있지만
# 따로 그래프 분할 해서 보는 방법도 있다. col이다.
# 더 정확히는 양옆으로 즉, 가로 배열로 분할하는 것은 col
# 세로 배열로 분할 하는 것은 row이다.
sns.set(font_scale = 1.5)
sns.lmplot(data = titanic, x = 'age', y = 'fare', aspect = 1, height = 8, col = 'sex')
# sns.lmplot(data = titanic, x = 'age', y = 'fare', aspect = 1, height = 8, row = 'sex')
plt.show()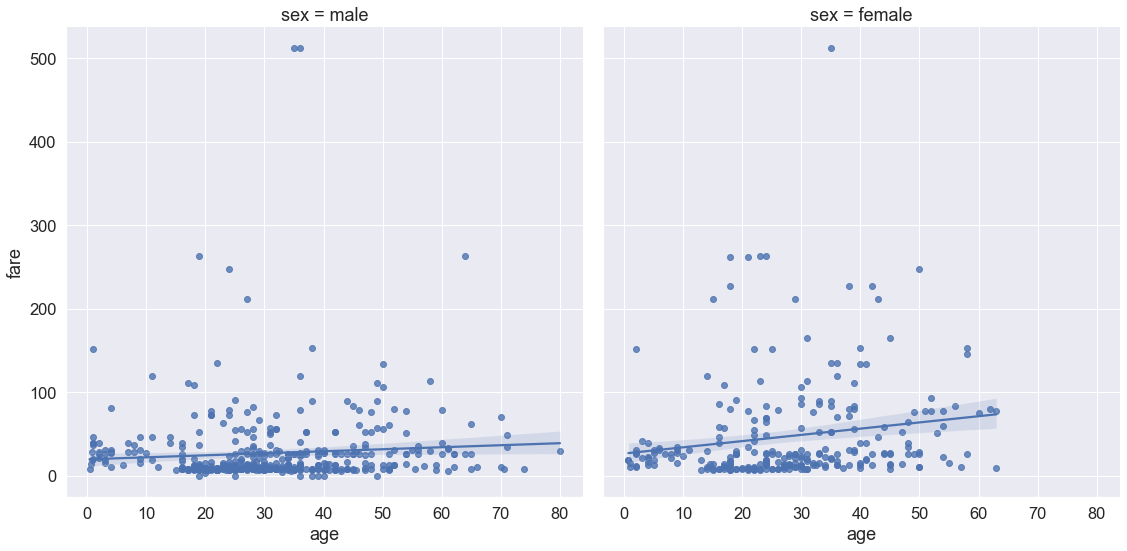
# logistic은 로지스틱 회귀의 형태를 의미한다.
sns.set(font_scale = 1.5)
sns.lmplot(data = titanic, x = 'age', y = 'survived', aspect = 1, height = 8, col = None, logistic = True)
plt.show()
# 근데 결과값을 봤을때 logistic을 True로 하나, False로 하나, 내눈에 달라진건 없는 것 같다.
sns.set(font_scale = 1.5)
sns.lmplot(data = titanic, x = 'age', y = 'survived', aspect = 1, height = 8, col = None, logistic = False)
plt.show()
# 아래로 내려가는 logistic 선형을 보인다면 컬럼값에 해당하는 (여기서는 나이)값이 낮을 수록 행 값에 해당하는 (여기서는 생존) 값이 높다는 것을
# 알 수 있다.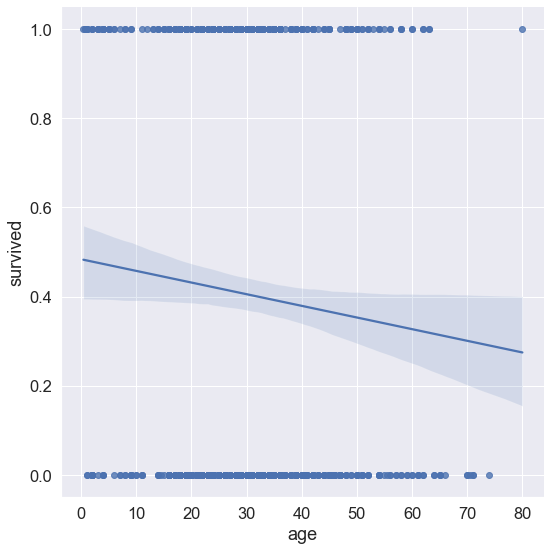
## Matrixplots / Heatmaps
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
titanic = pd.read_csv('titanic.csv')
titanic.head()
'''
survived pclass sex age sibsp parch fare embarked deck
0 0 3 male 22.0 1 0 7.2500 S NaN
1 1 1 female 38.0 1 0 71.2833 C C
2 1 3 female 26.0 0 0 7.9250 S NaN
3 1 1 female 35.0 1 0 53.1000 S C
4 0 3 male 35.0 0 0 8.0500 S NaN
'''pd.crosstab(titanic.sex, titanic.pclass)
'''
pclass 1 2 3
sex
female 94 76 144
male 122 108 347
'''
# 수치를 봤을때, 대체로 그룹의 값이 100 전후인데 male, 3등 객실에 대한 그룹의 값은 347이다.
# 그럴 경우 이런 특이값이 있는 수치는 배제하고 계산해줘야 유의미한 결과값이 나온다.# 위에서 봤듯이, 한개의 그룹값이 이상치가 있는 경우가 있었다.
# 따라서, 그 그룹이 필터링되어서 값이 나오지 않도록 상한값을 설정한다.
# 상한치 설정하는 변수는 vmax이다.
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.4)
sns.heatmap(pd.crosstab(titanic.sex, titanic.pclass), annot = False, fmt = 'd', cmap = None, vmax = 150)
plt.show()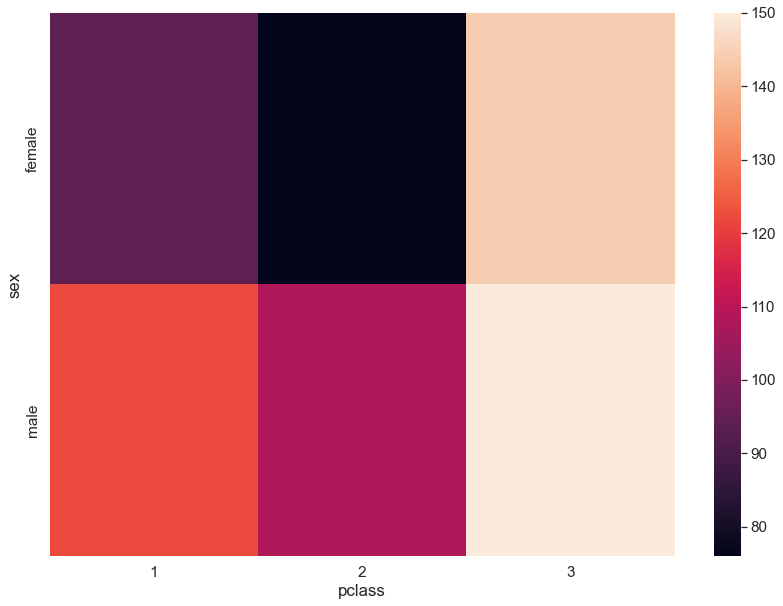
pd.crosstab(titanic.sex, titanic.pclass, values = titanic.survived, aggfunc = 'mean')
'''
pclass 1 2 3
sex
female 0.968085 0.921053 0.500000
male 0.368852 0.157407 0.135447
'''# annot은 수치표현을 의미한다.
plt.figure(figsize = (14,10))
sns.set(font_scale = 1.4)
sns.heatmap(pd.crosstab(titanic.sex, titanic.pclass, values = titanic.survived, aggfunc = 'mean'),
annot = True, cmap = 'Reds')
plt.show()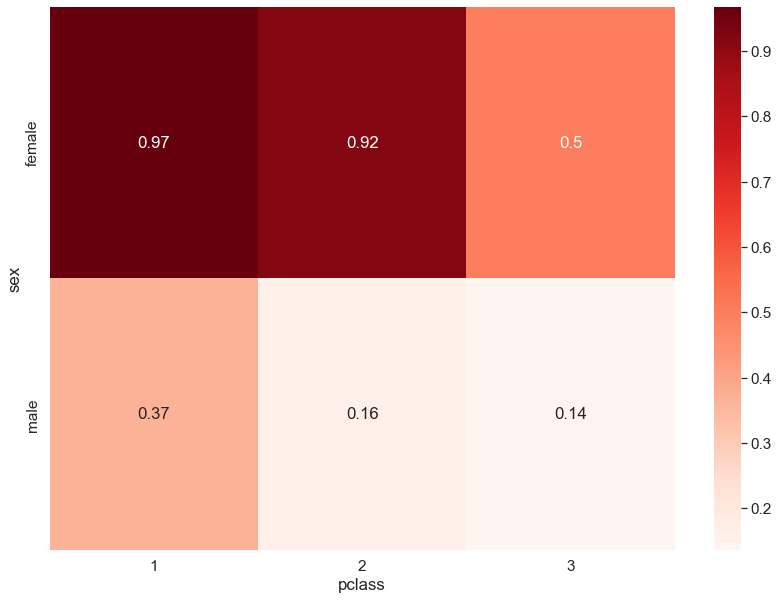
# 수치형 열의 상관관계 매트릭스
# corr()
titanic.corr()
'''
survived pclass age sibsp parch fare
survived 1.000000 -0.338481 -0.077221 -0.035322 0.081629 0.257307
pclass -0.338481 1.000000 -0.369226 0.083081 0.018443 -0.549500
age -0.077221 -0.369226 1.000000 -0.308247 -0.189119 0.096067
sibsp -0.035322 0.083081 -0.308247 1.000000 0.414838 0.159651
parch 0.081629 0.018443 -0.189119 0.414838 1.000000 0.216225
fare 0.257307 -0.549500 0.096067 0.159651 0.216225 1.000000
'''plt.figure(figsize = (14,10))
sns.set(font_scale = 1.4)
sns.heatmap(titanic.corr(), annot = True, cmap = 'Reds')
plt.show()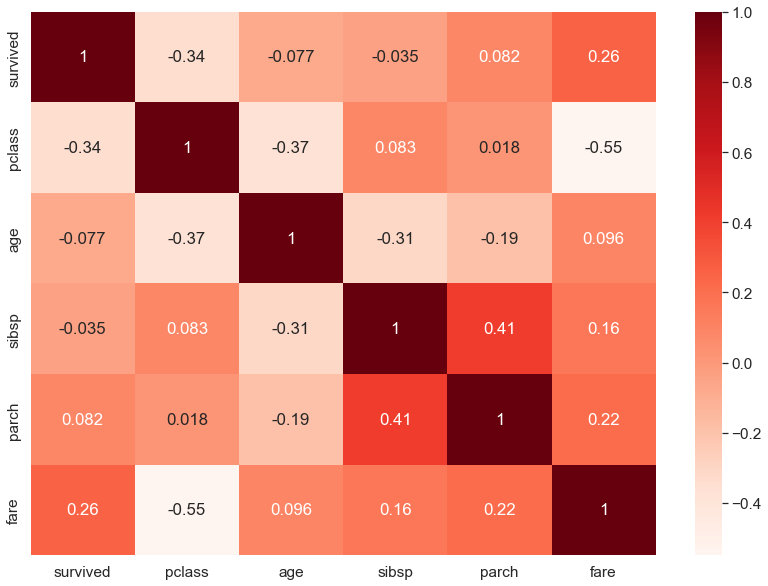
300x250
'개발일지 > 임시카테고리' 카테고리의 다른 글
| SQL 기초 3 BETWEEN 및 타임스탬프(timestamp) ft. SQLD 자격증 응시 취소 (0) | 2022.08.20 |
|---|---|
| pandas 판다스 기초 23 replace 응용 중요 루틴 및 dropna등 데이터 클리닝 여태까지 배운것 활용 (0) | 2022.08.19 |
| pandas 판다스 틀린문제 11 비율에 따른 구간 나누기 qcut, map과 dictionary로 변경값을 새로운 컬럼에 저장 루틴 (0) | 2022.08.19 |
| SQL 기초2 기본문법 사용 순서 및 PostgreSQL 리뷰 (0) | 2022.08.19 |
| (해결)과제 1 postgresql 슬로우 쿼리 해결방법 찾기 (0) | 2022.08.18 |
